07 Feb

PageRank (PR) is an algorithm that improves the quality of search results by using links to measure the importance of a page. It considers links as votes, with the underlying assumption being that more important pages are likely to receive more links.
PageRank was created by Google co-founders Sergey Brin and Larry Page in 1997 when they were at Stanford University, and the name is a reference to both Larry Page and the term “webpage.”
In many ways, it’s similar to a metric called “impact factor” for journals, where more cited = more important. It differs a bit in that PageRank considers some votes more important than others.
By using links along with content to rank pages, Google’s results were better than competitors. Links became the currency of the web.
Want to know more about PageRank? Let’s dive in.
In terms of modern SEO, PageRank is one of the algorithms comprising Experience Expertise Authoritativeness Trustworthiness (E-E-A-T).
Google’s algorithms identify signals about pages that correlate with trustworthiness and authoritativeness. The best known of these signals is PageRank, which uses links on the web to understand authoritativeness.
Source: How Google Fights Disinformation
We’ve also had confirmation from Google reps like Gary Illyes, who said that Google still uses PageRank and that links are used for E-A-T (now E-E-A-T).
When I ran a study to measure the impact of links and effectively removed the links using the disavow tool, the drop was obvious. Links still matter for rankings.
PageRank has also been a confirmed factor when it comes to crawl budget. It makes sense that Google wants to crawl important pages more often.
Crazy fact: The formula published in the original PageRank paper was wrong. Let’s look at why.
PageRank was described in the original paper as a probability distribution—or how likely you were to be on any given page on the web. This means that if you sum up the PageRank for every page on the web together, you should get a total of 1.
Here’s the full PageRank formula from the original paper published in 1997:
PR(A) = (1-d) + d (PR(T1)/C(T1) + … + PR(Tn)/C(Tn))
Simplified a bit and assuming the damping factor (d) is 0.85 as Google mentioned in the paper (I’ll explain what the damping factor is shortly), it’s:
PageRank for a page = 0.15 + 0.85 (a portion of the PageRank of each linking page split across its outbound links)
In the paper, they said that the sum of the PageRank for every page should equal 1. But that’s not possible if you use the formula in the paper. Each page would have a minimum PageRank of 0.15 (1-d). Just a few pages would put the total at greater than 1. You can’t have a probability greater than 100%. Something is wrong!
The formula should actually divide that (1-d) by the number of pages on the internet for it to work as described. It would be:
PageRank for a page = (0.15/number of pages on the internet) + 0.85 (a portion of the PageRank of each linking page split across its outbound links)
It’s still complicated, so let’s see if I can explain it with some visuals.
1. A page is given an initial PageRank score based on the links pointing to it. Let’s say I have five pages with no links. Each gets a PageRank of (1/5) or 0.2.
2. This score is then distributed to other pages through the links on the page. If I add some links to the five pages above and calculate the new PageRank for each, then I end up with this:
You’ll notice that the scores are favoring the pages with more links to them.
3. This calculation is repeated as Google crawls the web. If I calculate the PageRank again (called an iteration), you’ll see that the scores change. It’s the same pages with the same links, but the base PageRank for each page has changed, so the resulting PageRank is different.
The PageRank formula also has a so-called “damping factor,” the “d” in the formula, which simulates the probability of a random user continuing to click on links as they browse the web.
Think of it like this: The probability of you clicking a link on the first page you visit is reasonably high. But the likelihood of you then clicking a link on the next page is slightly lower, and so on and so forth.
If a strong page links directly to another page, it’s going to pass a lot of value. If the link is four clicks away, the value transferred from that strong page will be a lot less because of the damping factor.

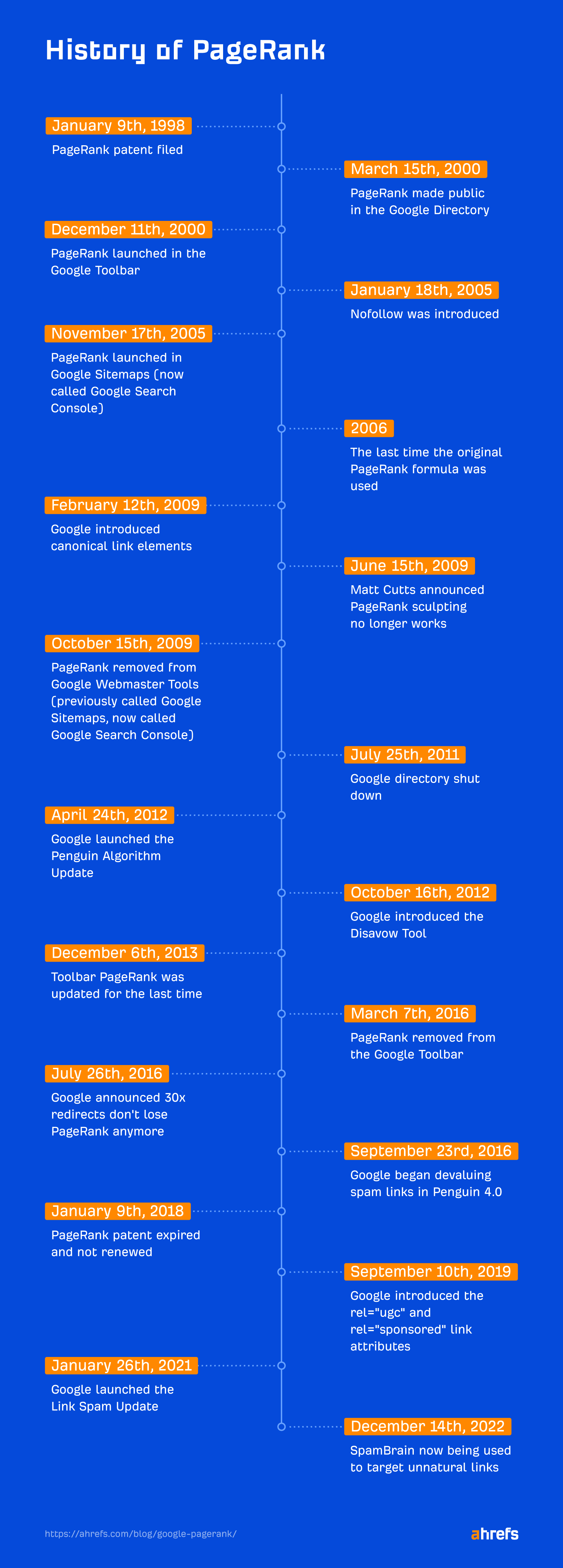
The first PageRank patent was filed on January 9, 1998. It was titled “Method for node ranking in a linked database.” This patent expired on January 9, 2018, and was not renewed.
Google first made PageRank public when the Google Directory launched on March 15, 2000. This was a version of the Open Directory Project but sorted by PageRank. The directory was shut down on July 25, 2011.
It was December 11, 2000, when Google launched PageRank in the Google toolbar, which was the version most SEOs obsessed over.
This is how it looked when PageRank was included in Google’s toolbar.

PageRank in the toolbar was last updated on December 6, 2013, and was finally removed on March 7, 2016.
The PageRank shown in the toolbar was a little different. It used a simple 0–10 numbering system to represent the PageRank. But PageRank itself is a logarithmic scale where achieving each higher number becomes increasingly difficult.
PageRank even made its way into Google Sitemaps (now known as Google Search Console) on November 17, 2005. It was shown in categories of high, medium, low, or N/A. This feature was removed on October 15, 2009.
Link spam
Over the years, there have been a lot of different ways SEOs have abused the system in the search for more PageRank and better rankings. Google has a whole list of link schemes that include:
- Buying or selling links—exchanging links for money, goods, products, or services.
- Excessive link exchanges.
- Using software to automatically create links.
- Requiring links as part of a terms of service, contract, or other agreement.
- Text ads that don’t use nofollow or sponsored attributes.
- Advertorials or native advertising that includes links that pass ranking credit.
- Articles, guest posts, or blogs with optimized anchor text links.
- Low-quality directories or social bookmark links.
- Keyword-rich, hidden, or low-quality links embedded in widgets that get put on other websites.
- Widely distributed links in footers or templates. For example, hard-coding a link to your website into the WP Theme that you sell or give away for free.
- Forum comments with optimized links in the post or signature.
The systems to combat link spam have evolved over the years. Let’s look at some of the major updates.
Nofollow
On January 18, 2005, Google announced it had partnered with other major search engines to introduce the rel=“nofollow” attribute. It encouraged users to add the nofollow attribute to blog comments, trackbacks, and referrer lists to help combat spam.
Here’s an excerpt from Google’s official statement on the introduction of nofollow:
If you’re a blogger (or a blog reader), you’re painfully familiar with people who try to raise their own websites’ search engine rankings by submitting linked blog comments like “Visit my discount pharmaceuticals site.” This is called comment spam, we don’t like it either, and we’ve been testing a new tag that blocks it. From now on, when Google sees the attribute (rel=“nofollow”) on hyperlinks, those links won’t get any credit when we rank websites in our search results.
Almost all modern systems use the nofollow attribute on blog comment links.
SEOs even began to abuse nofollow—because of course we did. Nofollow was used for PageRank sculpting, where people would nofollow some links on their pages to make other links stronger. Google eventually changed the system to prevent this abuse.
In 2009, Google’s Matt Cutts confirmed that this would no longer work and that PageRank would be distributed across links even if a nofollow attribute was present (but only passed through the followed link).
Google added a couple more link attributes that are more specific versions of the nofollow attribute on September 10, 2019. These included rel=“ugc” meant to identify user-generated content and rel=“sponsored” meant to identify links that were paid or affiliate.
Algorithms targeting link spam
As SEOs found new ways to game links, Google worked on new algorithms to detect this spam.
When the original Penguin algorithm launched on April 24, 2012, it hurt a lot of websites and website owners. Google gave site owners a way to recover later that year by introducing the disavow tool on October 16, 2012.
When Penguin 4.0 launched on September 23, 2016, it brought a welcome change to how link spam was handled by Google. Instead of hurting websites, it began devaluing spam links. This also meant that most sites no longer needed to use the disavow tool.
Google launched its first Link Spam Update on July 26, 2021. This recently evolved, and a Link Spam Update on December 14, 2022, announced the use of an AI-based detection system called SpamBrain to neutralize the value of unnatural links.
The original version of PageRank hasn’t been used since 2006, according to a former Google employee. The employee said it was replaced with another less resource-intensive algorithm.
They replaced it in 2006 with an algorithm that gives approximately-similar results but is significantly faster to compute. The replacement algorithm is the number that’s been reported in the toolbar, and what Google claims as PageRank (it even has a similar name, and so Google’s claim isn’t technically incorrect). Both algorithms are O(N log N) but the replacement has a much smaller constant on the log N factor, because it does away with the need to iterate until the algorithm converges. That’s fairly important as the web grew from ~1-10M pages to 150B+.
Remember those iterations and how PageRank kept changing with each iteration? It sounds like Google simplified that system.
What else has changed?
Some links are worth more than others
Rather than splitting the PageRank equally between all links on a page, some links are valued more than others. There’s speculation from patents that Google switched from a random surfer model (where a user may go to any link) to a reasonable surfer model (where some links are more likely to be clicked than others so they carry more weight).
Some links are ignored
There have been several systems put in place to ignore the value of certain links. We’ve already talked about a few of them, including:
- Nofollow, UGC, and sponsored attributes.
- Google’s Penguin algorithm.
- The disavow tool.
- Link Spam updates.
Google also won’t count any links on pages that are blocked by robots.txt. It won’t be able to crawl these pages to see any of the links. This system was likely in place from the start.
Some links are consolidated
Google has a canonicalization system that helps it determine what version of a page should be indexed and to consolidate signals from duplicate pages to that main version.
Canonical link elements were introduced on February 12, 2009, and allow users to specify their preferred version.
Redirects were originally said to pass the same amount of PageRank as a link. But at some point, this system changed and no PageRank is currently lost.
A bit is still unknown
When pages are marked as noindex, we don’t exactly know how Google treats the links. Even Googlers have conflicting statements.
According to John Mueller, pages that are marked noindex will eventually be treated as noindex, nofollow. This means that the links eventually stop passing any value.
According to Gary, Googlebot will discover and follow the links as long as a page still has links to it.
These aren’t necessarily contradictory. But if you go by Gary’s statement, it could be a very long time before Google stops crawling and counting links—perhaps never.
There’s currently no way to see Google’s PageRank.
URL Rating (UR) is a good replacement metric for PageRank because it has a lot in common with the PageRank formula. It shows the strength of a page’s link profile on a 100-point scale. The bigger the number, the stronger the link profile.
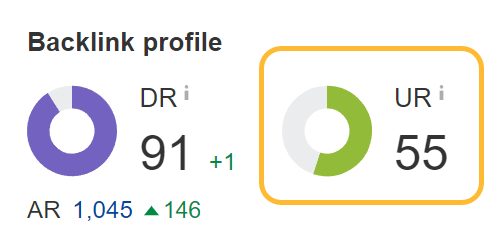
Both PageRank and UR account for internal and external links when being calculated. Many of the other strength metrics used in the industry completely ignore internal links. I’d argue link builders should be looking more at UR than metrics like DR, which only accounts for links from other sites.
However, it’s not exactly the same. UR does ignore the value of some links and doesn’t count nofollow links. We don’t know exactly what links Google ignores and don’t know what links users may have disavowed, which will impact Google’s PageRank calculation. We also may make different decisions on how we treat some of the canonicalization signals like canonical link elements and redirects.
So our advice is to use it but know that it may not be exactly like Google’s system.
We also have Page Rating (PR) in Site Audit’s Page Explorer. This is similar to an internal PageRank calculation and can be useful to see what the strongest pages on your site are based on your internal link structure.
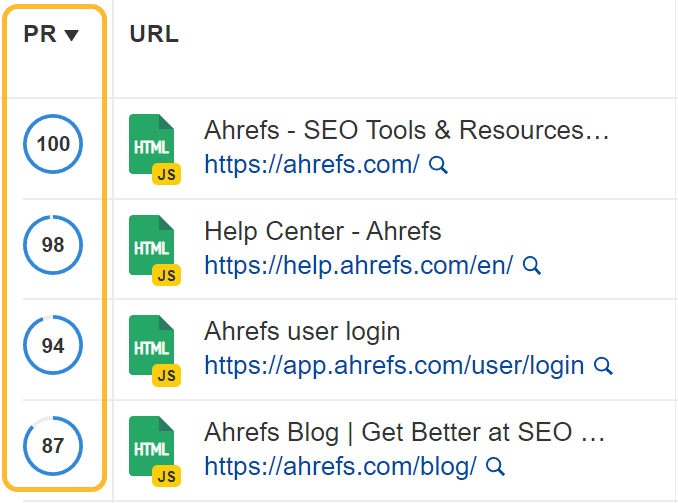
Since PageRank is based on links, to increase your PageRank, you need better links. Let’s look at your options.
Redirect broken pages
Redirecting old pages on your site to relevant new pages can help reclaim and consolidate signals like PageRank. Websites change over time, and people don’t seem to like to implement proper redirects. This may be the easiest win, since those links already point to you but currently don’t count for you.
Here’s how to find those opportunities:
I usually sort this by “Referring domains.”
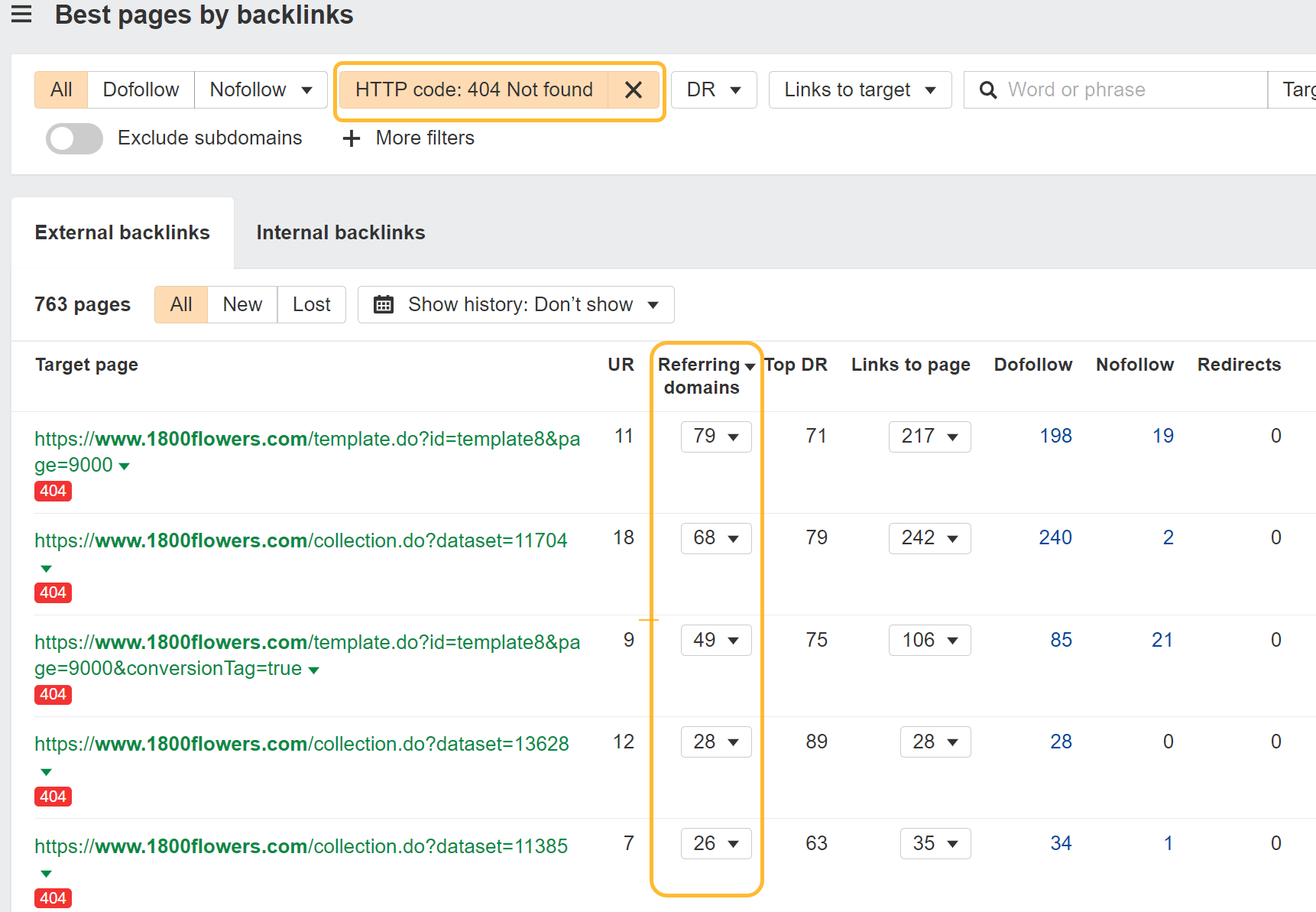
Take those pages and redirect them to the current pages on your site. If you don’t know exactly where they go or don’t have the time, I have an automated redirect script that may help. It looks at the old content from archive.org and matches it with the closest current content on your site. This is where you likely want to redirect the pages.
Internal links
Backlinks aren’t always within your control. People can link to any page on your site they choose, and they can use whatever anchor text they like.
Internal links are different. You have full control over them.
Internally link where it makes sense. For instance, you may want to link more to pages that are more important to you.
We have a tool within Site Audit called Internal Link Opportunities that helps you quickly locate these opportunities.
This tool works by looking for mentions of keywords that you already rank for on your site. Then it suggests them as contextual internal link opportunities.
For example, the tool shows a mention of “faceted navigation” in our guide to duplicate content. As Site Audit knows we have a page about faceted navigation, it suggests we add an internal link to that page.

External links
You can also get more links from other sites to your own to increase your PageRank. We have a lot of guides around link building already. Some of my favorites are:
Final thoughts
Even though PageRank has changed, we know that Google still uses it. We may not know all the details or everything involved, but it’s still easy to see the impact of links.
Also, Google just can’t seem to get away from using links and PageRank. It once experimented with not using links in its algorithm and decided against it.
So we don’t have a version like that that is exposed to the public but we have our own experiments like that internally and the quality looks much much worse. It turns out backlinks, even though there is some noise and certainly a lot of spam, for the most part are still a really really big win in terms of quality of search results.
We played around with the idea of turning off backlink relevance and at least for now backlinks relevance still really helps in terms of making sure that we turn the best, most relevant, most topical set of search results.
Source: YouTube (Google Search Central)
If you have any questions, message me on Twitter.
Source: ahrefs.com, originally published on 2023-02-07 00:38:00

![How to Successfully Use Social Media: A Small Business Guide for Beginners [Infographic]](https://dev.b2webstudios.com/storage/2023/02/How-to-Successfully-Use-Social-Media-A-Small-Business-Guide-85x70.jpg)



![How to Successfully Use Social Media: A Small Business Guide for Beginners [Infographic]](https://dev.b2webstudios.com/storage/2023/02/How-to-Successfully-Use-Social-Media-A-Small-Business-Guide-300x169.jpg)

Recent Comments